As we all have seen trying to predict into the future is often more informative and enjoyable looking back on the predictions from the future than reading the predictions in the present. With that in mind I’m going to keep the future of the web to the near future. Also this will be heavily biased towards the technical side of the future and not so much on how that will change our selves our social interactions and our educations. The technical side is a bit clearer, it’s something I’m assuming many of you don’t know too much about which you know much more about the personal and social side. And quite frankly I’m more interested in exploring the human side in discussion and not in a post.
If you only read only one of the many links that will be here read the next one. In it Sir Tim Berners-Lee, the creator of the Web (which is different from and built on the Internet), breaks it down as he sees it. The article is heavily paginated so I suggest clicking on the print button to see it all on one scrollable page: Long Live the Web.
Future of Web Technology
Web 3.0 / Semantic Web
There are a number of names for this but the idea is that in the future it will be easier for computers to talk to each other. As a programmer I prefer to think of it as a future where it is easier for people to write programs that can find and connect data and interact with other programs without the need for human intervention.
Right now we are in a stage where most of what is on the web is one of two things: people publishing information (like blogs and wikis and many web sites), and people using applications on the web (like Facebook, Gmail). Some of this is computers interacting directly with each other, but not much. One of the main reasons is that HTML itself is a pretty vague language. When you define content on a page you can only define general things like titles, paragraphs, lists.
This means that I have a hard time writing a program that can just go to a web site and find out specific information about the site. Google starts to do this but they can only do so much. What is needed are defined standards for how to describe certain types of information that might exist on a site. This is already being started with microformats. These are basically simple formats that use existing HTML but in a predetermined format. When I just visited the site the latest news announced that Google now has a new microformat recipe search. People who have recipes and put them in the recipe microformat will have those indexed and make searchable by Google.
The other method for allowing programs to talk to each other we currently have is APIs (Application Programming Interfaces). When a company writes an API for their service they are essentially opening up part of their data and functionality to programmers outside of their company. These APIs allow us to do things like pull in data from Google into our applications and reuse them. The combining of data and functionality from different services is often called a mashup. This is mashup from one of my students that brings Google Maps and Google Local Search into Flash. As we move forward it’s expected that these APIs will become more common and easier to integrate. For an idea of just how many are out there now here’s Programmable Web’s list: http://www.programmableweb.com/apis/directory
The idea going forward is that you will be able to do things like look for books your friends like and in the background the program will be able to search through their Facebook updates, likes, twitter feed, blog posts and emails to you and find actual books your actual friends like. For an idea of what that might be like try adding all of your feeds to Memolane. This uses oAuth open authentication and the various APIs from different social services to create a timeline of your life on the web (at least as seen through things like Facebook, Twitter and blogs).
And coordination among services will be possible in new ways. When you buy a concert ticket it might put the information in your calendar, notify your partner for whom you also bought a ticket, ask if you want dinner reservations nearby, with a list of possible places and friend recommendations for those places, offer you the option to tweet about it, pull the weather for the day and add a reminder for you to bring an umbrella.
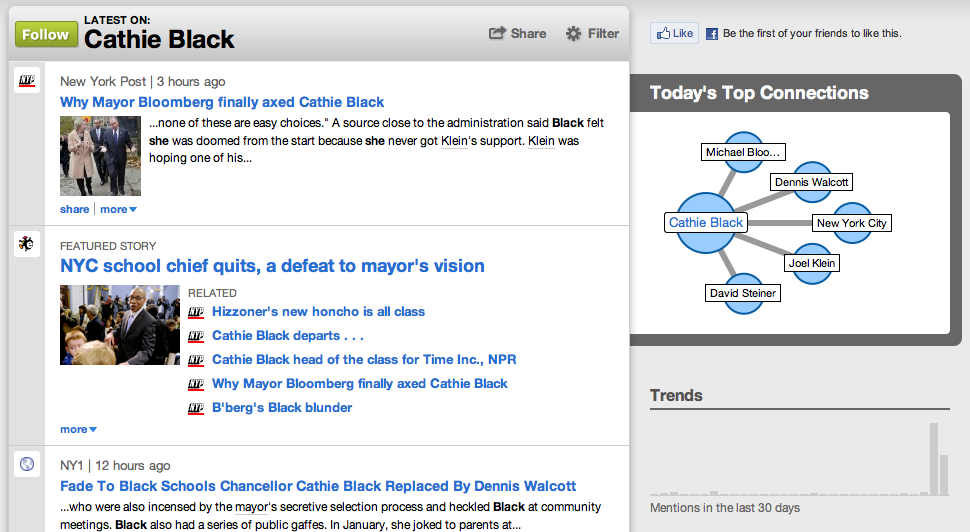
In a more educational vein, the tools we use to search for and gather information will be much better at recognizing related and connected information. Try the search engine Evri for a kind of preview. Below is a screenshot of a search for Cathie Black (ousted yesterday as NYC Schools Chancellor) where it shows stories that are current and related to her and even recognizes and links other people.

If you follow this link: http://www.evri.com/news/for?query=cathie+black it will show yhou a list of stories and on the right have a list of people to help qualify who you were looking for. Click on the Cathie Black link on that list and you’re taken to this page http://www.evri.com/person/cathie-black-0x574bd7 which is the one where I grabbed the screenshot.
If you’re interested in more on Web 3.0 in non-academic speak here are some links:
http://computer.howstuffworks.com/web-303.htm
http://www.labnol.org/internet/web-3-concepts-explained/8908/
Standards
Standards are what have helped drive the internet to this point and they are most likely what will continue to drive it into the future. In the short term we are in the middle of an update to two of the venerable standards: HTML and CSS. HTML is moving to HTML5 and CSS is moving to CSS3. These standards will provide a more robust and flexible base which will make both the semantic web and also general web publishing and viewing better and easier.
For a long look at how they are effecting how we read you can view a post I did about the future of eReading.
Unfortunately in education we have not been able to adopt many easy open standards to help manage our classes, administration and research. For a very in-depth look at these standards (it’s a lot I haven’t been able to get through it yet), this series of articles on IBM’s web site should give you a full perspective (the first and last give a kind of overview/summary).
Technical standards in education, Part 1: Introducing the educational standards
Technical standards in education, Part 2: Learning technology standards, specifications, and protocols
Technical standards in education, Part 3: Open repositories for scholarly communication
Technical standards in education, Part 4: Interoperable resource deposit using SWORD
Technical standards in education, Part 5: Take advantage of metadata
Technical standards in education, Part 6: Standards for assessment and item banks
Technical Standards in Education, Part 7: Web 2.0, sharing, and the open agenda
The simplest way to make sure you are able to at least take part in the latest standards is to Update Your Browser on a regular basis. Now all major browsers (Firefox, Chrome, Safari, Opera and, yes, Internet Explorer) do a pretty good job of being standards compliant.
Interfaces
The web is just a structured set of data built on the underlying structure of the internet for communicating that information between computers. The “computers” that access the internet will group. It’s not just a PC with a browser anymore. In regular use are pc, laptop, netbook, tablet and smartphone. Soon that will include many more devices like refrigerators, cars, home security systems, etc. As the devices expand so will the interfaces we use. These interfaces will move from just keyboard/mouse(old skool), to touch (already done), gesture and voice (on the way despite Google’s April Fool’s Day prank)
These interfaces are being developed and will continue to be developed to get the kinks out. As with iOS and Android it seems that each revolutionary interface also requires a new operating system. This video is an example of a proposed multitouch system that would need a new OS. Multitouch video: http://10gui.com/video/ (R. Clayton Miller)
One of the negative features of these new devices is that they will create more walled gardens. By “walled gardens” I’m referring to the fact that they often run a subset of what is available on the internet. For example although smartphones have browsers much of what people do on them is in the form of apps. In Apple’s case the availability of the apps is also under central control. The internet as used in your car will also likely be usually through an app that has a targeted focus. It will become increasingly easier to play in a corner of the internet the walls of which are determined by OS and app makers, even if we can spruce up the place a bit with out personal info.
Software as a Service (SaaS)
SaaS is simply put, software that we don’t have to download or install but simply point our browser to and use. Google is a big supplier of this kind of software with Gmail, Google Docs and more. Small companies like Avairy have never been anything but SaaS. Microsoft, Adobe and most major software vendors have jumped into the game in some fashion. This trend will continue with more, and more sophisticated software. Also you will see more services that, like Evernote, offer their product in multiple ways: web service, desktop app, and mobile app.
Augmented Reality
This loosely refers to adding a digital layer on top of the real world in some way. On the at-home end of the spectrum are apps like this one by GE: http://ge.ecomagination.com/smartgrid/#/augmented_reality. If you don’t want to both with printing out a marker and making sure your microphone and web cam are turned on then you can just click the video on the left. This uses image recognition from the webcam to drive a 3d rendering and the volume on your microphone to turn the windmills. Moving out into the world QR codes allow you to point your phones camera at one of the QR codes and be taken to a web site. Not too complicated but it requires a smartphone to work. A bit more exciting are the phone-based AR apps that map data onto an your phone’s live camera display. You can find bars, subway stations, constellations and play games. While these are exciting they also pose new challenges to the meaning of privacy. Using things like facial recognition it’s not hard to imagine an app that could be pointed at random people walking down the street and show you their names, Tweets, Facebook updates and more.
Some AR links:
http://mashable.com/2009/12/05/augmented-reality-iphone/
http://www.revenews.com/ctmoore/augmented-reality-threatens-physical-property-rights/
http://eu.techcrunch.com/2010/07/19/zoopla-launches-iphone-app-for-uk-property-with-augmented-reality/
Openness
While there are technology driven and social (authoritarian) forces that are making the internet less open, there is still hope for more openness, both in the technology, as in open source and in the content and relations as in the open government and open education movements.
Some kinks to government and education related open resources
http://www.data.gov/
http://data.gov.uk/
http://en.wikipedia.org/wiki/Open_education
http://www.openeducation.net/
http://www.ocwconsortium.org/
http://www.oercommons.org/
http://ocw.mit.edu/index.htm
http://oyc.yale.edu/
http://openeducationnews.org/
http://www.merlot.org
http://openstudy.com/
http://www.opentextbook.org/
http://www.hippocampus.org
http://ww.gutenberg.org
http://en.wikibooks.org
http://www.collegeopentextbooks.org
See this Wikipedia page for an extensive list of open source software:
http://en.wikipedia.org/wiki/List_of_free_and_open_source_software_packages
IDENTITY / INTERACTIONS / CONNECTIONS
As I mentioned earlier I won’t spend much time here. It seems relatively certain that as the web changes and grows it will change the way see ourselves, interact with other people and the world and the connections we make with other people. Sometimes it will be useful to have an identity that you can take with you across sites so you don’t have to keep entering the same information everywhere. Other times it will be useful to have an identity that is anonymous and not traceable back to you. Will that be possible?
Social Networking is clearly going strong and will stay that way. Although it seems at some point Facebook won’t be able to have such a monolithic hold on the space. The challenge may come from another country. There is still an imbalance of English speaking and European people on the web. Much of the future will be about the rest of the world coming onto and reshaping it. Berners-Lee also has some thoughts on this internationalization and the human right to connect with other humans: http://bit.ly/eaEUGz.

{kind=link}
Thanks for the post, Chris. Much of this is very new to me.
I’m glad that you called our attention to how rights relate to the future of the Web, both in the “Electronic Rights” section of the first of Tim Berners-Lee’s articles and in the article to which you linked in the “Augmented Reality” section of your post.
The Universal Declaration of Human Rights, founds contemporary Human Rights discourse upon a particularly embodied notion of the Human. Claiming, as Berners-Lee does, that these humans have the right to become disembodied (that is, to represent themselves in cyberspace, an inevitable consequence of universal Internet access) strikes me at once as both necessarily humanist and inherently problematic. What “rights” do we have once we’re online? How well will the “person”–the legal receptacle for all the messiness that comes with the notion of “human”–hold up as our identities become more digital in the coming years?
Looking forward to hearing more about the future of the Web tomorrow,
Erin